January 23, 2025
Leading a team to build and deliver a Production RAG-based Ad Analytics Platform
Back in July 2024, I was picked to build a data/software application (along with 5 others) by RMIT University. This was an amazing opportunity. I get to work on something that needed to be used in production and could have real impact. Exactly what I needed, as someone with no prior professional data/engineering experience. The fact that I was picked to lead the team made it even better. This was going to be a true challenge. So this is how we did it.
Let’s start off with the actual requirements. It would be horrifically messy to begin a project without a proper PRD. As the lead, this was my first task. We met with our industry supervisor (i.e., my boss for the project), Bob Xiao, who was incredibly supportive throughout this journey. We did not proceed till we had a solid set of requirements, user stories and the like. Getting this out of the way was great because we now had a clear view and could go ahead with design docs, planning etc.
So the main requirement was to build a dashboard to help users analyse ads published by RMIT’s competitors on Google. This meant detailed keyword frequency analysis, ad frequencies, tone etc. An additional, but crucial, requirement was to leverage GPT 4o (state of the art at the time, crazy) to generate ads based on RMIT’s historical ads. Putting this together sounds easy but building a web application that brought all of this together was anything but easy.
We were also mandated to deploy the application on AWS. We stumbled upon AWS’ Well-Architected Framework early on and knew right away that following this framework was important. As the technical lead for this project, my primary goal was to architect an application that would be less expensive and more efficient than the previous attempts from earlier semesters. So I began preparing the design doc around those principles. What I ended up with was somewhat comprehensive, even at a high level.

I should provide some rationale for the choices here. From my experience of building a few personal projects, I knew how difficult it would be to implement auth from scratch. Sure, we could’ve done it, but there was no need to reinvent the wheel. AWS Cognito’s tooling is practically plug and play so we went ahead with it for auth. Now, every action that would be performed by a user was going to be stateless, given the nature of this application and the requirements. This application also did not require backend services that had to be running 24/7. So we adopted a fully serverless, event-driven architecture with Lambda functions. For the database, I did not have to look any further. RDS with PostgresQL along with vector storage support was exactly what this application needed. With the AWS side of things out of the way, let’s talk about the external services we used. OpenAI’s APIs are/were cheap and incredibly easy to use. But it was not as crucial as SERP, which is what allowed us to collect competitor ads data. This allowed us to collect ads, in particular, for specific keywords. For the front-end, Next.js/React was a no-brainer. The community support and the very existence of Shadcn/ui is enough to pick a JS framework. We went this way to ensure the best possible user experience and boy did we deliver that!
The time to start implementing the architecture had come. We began our work and quickly hit roadblocks with Python and managing its dependencies. This was our first taste of an ‘it works on my machine!’ situation. After a little bit of work we decided to involve containers and AWS Elastic Container Registry for our Lambda functions. Setting up the container was a pain the first time but the rest of the development process was a BREEZE. All we had to do was setup Github Actions and Docker to push to ECR, we were flying.
I personally built the analytics side of things in its entirety, along with auth. These were the most fun parts of this project as I got to learn some complex SQL involving CTEs, ranking etc. and how robust auth systems worked. We initially had to build auth in such a way that only RMIT users (users with an RMIT email address) could access. But this changed as external agency users may also use the platform. So I built an invite-based sign up process along with full Role-Based Access Control.
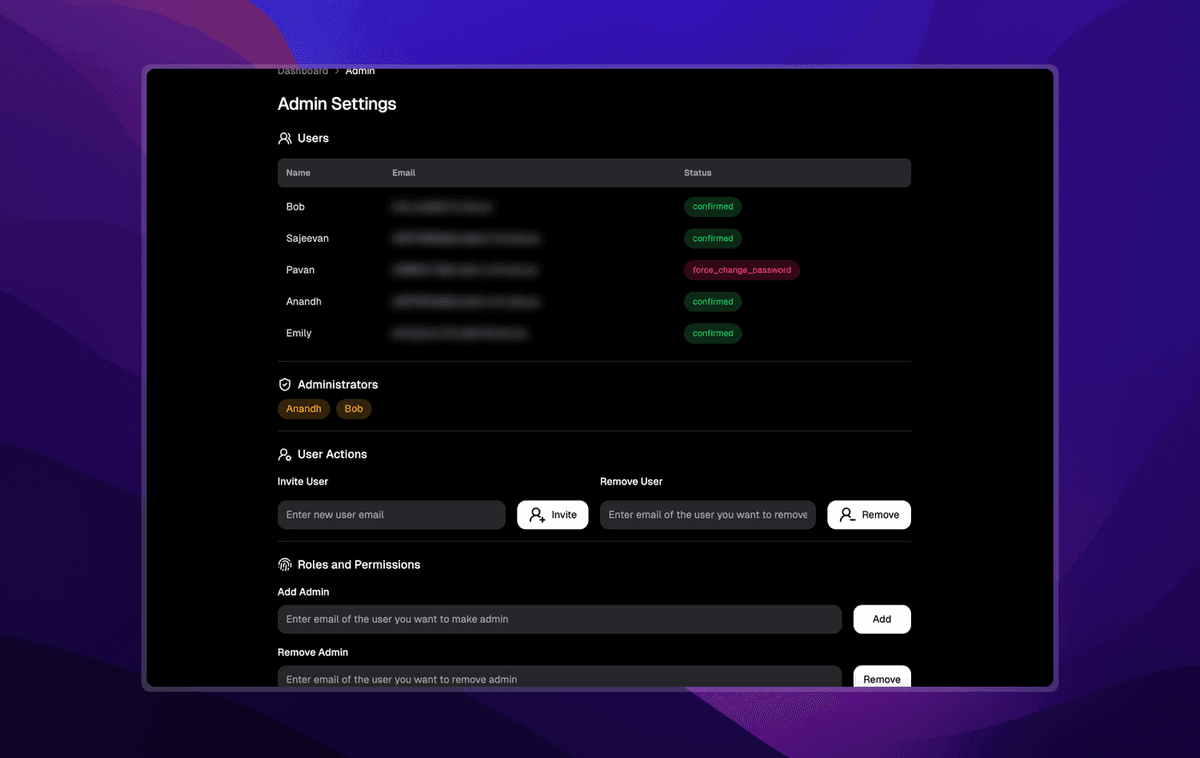
This was initially daunting as I always thought an auth system like this would be extremely complex. But after breaking down the problem into small steps, I immediately knew what I had to do. The idea was simple: The platform should have RBAC, so that only admins can add or remove users. So I quickly put together an ‘Admin Settings’ page as shown in the screenshot above (Thanks Shadcn and NextUI). I quickly created a table in our database to store email addresses and UUIDs that will later be used for the invite links. A lambda function was created to: Perform CRUD operations on the user pool using Cognito’s API, generate UUIDs which will be stored in the table and verify said UUIDs when a user tries to access the sign-up route. On the front-end, I setup a dynamic route under ‘/sign-up/[id]’.
So the flow would be as follows: Admin adds a user on the UI and gets an invite link in return, this contains the UUID generated by the Lambda function → The email address and UUID are stored in the database → The admin shares this invite link to the user, and when they try to access this page, the front-end calls the Lambda function to verify if the UUID exists and if it is still valid if both are true, the page renders. If not, they will not be able to access the sign up page. Oh, and I also set up a step function to clean up expired invite UUIDs. I was, and am still, very proud of this as I did all of this in a single day.


Analytics were quite challenging to implement. The previous iteration of this project simply displayed a table containing ad statistics but we wanted to go a few steps further. So we redid most of the existing analytics backend. The previous team had to build this on top of DynamoDB (due to the lack of vector databases with SQL functionalities at the time). This meant that the backend had to fetch the ENTIRE table and perform operations on data. It would take over 25s to return statistics and would only get significantly worse as the database grew. Switching to RDS with Postgres made this significantly faster. The built in cosine distance function, along with the ability to write SQL were enough for us to gain a 5x speed up. Given the rigid requirements for analytics, we were able to implement quite a bit of the business logic as SQL queries. This of course will not scale well but the platform will never have more than 5-7 concurrent users so it was okay. Optimising this, considering all the factors, would be premature so we stuck to this. I put together a few Shadcn Charts on the frontend to visualise the statistics. This was a massive update.
I’m sorry for only just starting to talk about the RAG aspects of this project. I got a little carried away with the other impressive systems we built. This bit will be about vector databases and retrieval, I promise.
We used SERP to collect competitors’ ads. We stored the search keywords and the ads’ headlines, descriptions and sources in RDS. The headlines were vectorised. Now you might wonder, ‘Gee Anandh you guys were storing the search keywords anyway so why perform vector based retrieval on the headlines?’ We wanted to rank the ads based on semantics. Additionally, simple text-based search did not always return what we were looking to analyse. With all this out of the way, we had a solid retrieval system which we could use to retrieve and rank ads from say, the last week or the last month or even the last year. I wrote SQL queries with CTEs and RANK to generate rankings based on the cosine distance. We could now pass the best matches every time to GPT as examples for tonal analysis and ad generation. This meant we could keep GPT’s generations aligned to ethical ad generation principles and avoided having it run wild with promises and guarantees.
Leading the team to deliver this was initially quite difficult as the team’s core strength was programming in Python. None of us had worked on a full stack project prior to this. This is where I got to apply the things I picked up from my previous managers and mentors. As a leader, it is important to provide a platform for everyone to succeed. So I made sure we had all the necessary resources to learn as well as apply what we learned. Regular group research and coding sessions helped a lot as we could bounce ideas off of and enable each other.
By building and delivering this, we are all significantly better equipped to enter the job market now than we were 6 months ago. Given the state of the job market at the moment, that is the biggest takeaway from all of this. We have to continue learning. We have to be so good, to the point of being irresistible (as weird as it sounds in this context). Since delivering this project, I’ve had over 50 applications rejected so I better get back to work 😂