Natural Language Processing to Classify Job Postings
Assignment, 2023
Timeline
September 2023 - October 2023
Tools
Python, NLTK, Sklearn, Gensim, React, Flask, AWS
Overview
Built a NLP/Logistic Regression model to classify job postings into categories. The model was trained on a dataset of 700 job postings. The deployed model achieved an accuracy and recall of ~80%. Also built a semi-decent React frontend around it.
Background
Full disclosure, this was not a personal project but a university assignment. Specifically, this spanned across 2 assignments for the Advanced Programming in Python course. This course focused on advanced programming (duh), regexes, natural language processing and web application development with Flask. I didn't particular enjoy building out templates via Flask for the frontend so instead I built a React app which consumed the APIs I wrote in Flask.
Properties
This assignment was split into 4 tasks. Task 1 involved preprocessing data while tasks 2 and 3 involved training and cross-validating models with different variations of the training data (i.e., training the model on weighted vectors and unweighted vectors separately) to analyse performance differences
Let's talk about task 1. We were given a decently large dataset of over 700 job postings (JP). Each JP was in its own file. There were four directories: Accounting, Engineering, Nursing and Sales. These were the 4 classes that the model I built, learned to predict accurately 80-90% of the time. So I started off by reading and storing the files in a specific format ('id', 'title', and 'description'). This came in handy for removing words using term and document frequencies. The initial dataset before any preprocessing had about 107k tokens. The final version had about 81k tokens. The tokens were saved as a .txt file, which would later be used for training the model.
Moving on to task 2 - this also began with loading the files to store the IDs, titles and descriptions in separate lists as task 1 and 2 along with 3 needed to be in separate Jupyter Notebooks. There was an additional subtask of generating count vectors. These are essentially just key:value pairs where the key is the word itself and the value is the frequency of that word. With that out of the way, let's get into the most interesting part of this project.
A FastText embedding model was used to generate feature vector representations for the titles and descriptions of each job posting. Initially, a version with TF-IDF weights was generated, followed by one without TF-IDF. Here's a simple explanation of what TF-IDF is in case you aren't aware: It is the product of term frequencies and inverse document frequency, i.e., it is the product of the number of times a word appears in one document and the number of times the same word appears in the rest of the corpus. The two versions of the vectors were used to analyse the performance gains we may see by using weighted vectors. And unsurprisingly, the model that was trained on the weighted vectors performed better.
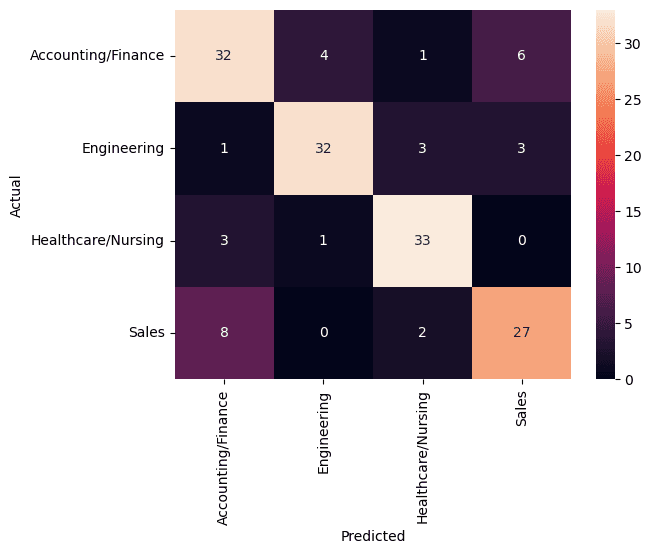
As you can see, the model trained on the weighted vectors performed quite well (an accuracy and recall of 90%). This was fantastic! The model trained on unweighted vectors was not horrifically poor but did result in a 10% decrease in accuracy and recall.
Fig 1. Confusion Matrix for TF-IDF weighted vectors model
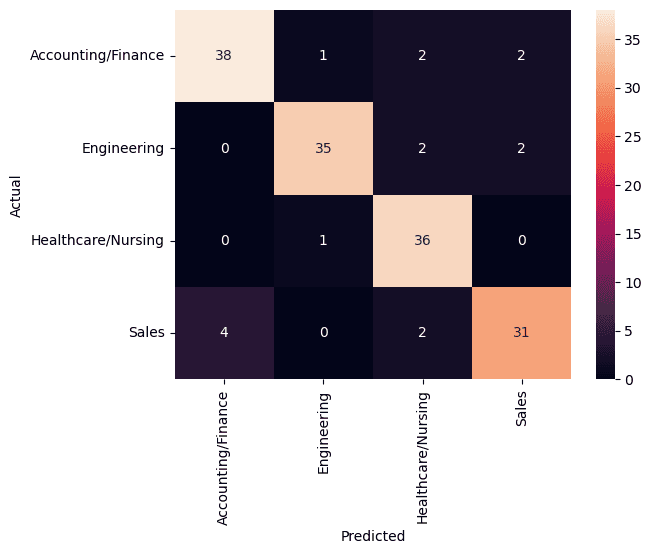
Fig 2. Confusion Matrix for the unweighted vectors model
I repeated the same but this time, only the titles were used. The performance difference between weighted and unweighted was extreme in this case. Weighted titles resulted in an accuracy and recall of ~78%, but the unweighted version was genuinely terrible.
Separately, I also trained a model with weighted vectors of both the titles and descriptions combined. This, obviously, resulted in better performance. No machine learning project is complete without cross-validation. I performed a 5-fold cross val which produced the following results:
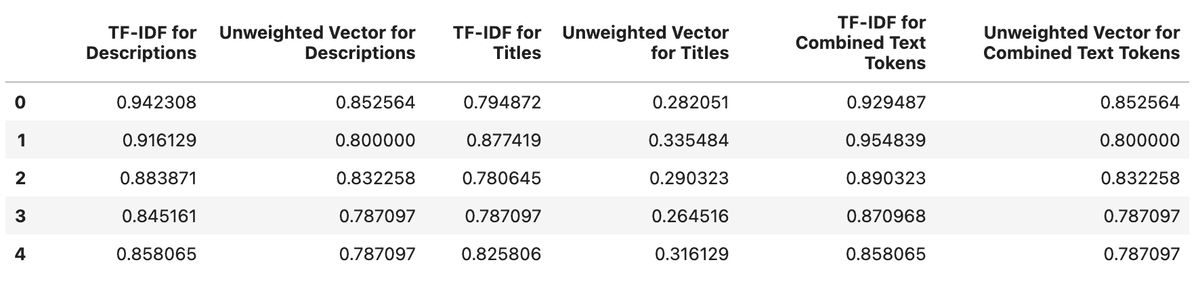
The model that can be used in production is clear at this point. So the model was saved as a pickle file and was served using Flask on the backend. I later dockerised the whole application and deployed it to an EC2 instance. Sadly, I had to take it down after a couple of days, fearing AWS bills.
Learnings
This was an incredibly complex project at the time but I had a ton of fun doing it. I started off having little to no idea of how language models worked (non-generative AI models) before I began working on this. Key learnings: TF-IDF, Embeddings, Model deployment and a ton of other things. This set off my 'learning by doing' journey and I've since built several end-to-end projects!